A. Compared with CLAY (Rodin Gen-1)
We evaluated a commercial product named Rodin via membership subscription on its website, which is based on the CLAY technique, since CLAY itself is not open-sourced.
It is worth noting that Rodin:
- is trained on proprietary internal datasets
- originates from CLAY, which was initially trained on 256 A800 GPUs for 15 days
- has undergone months of updates incorporating sophisticated techniques such as RLHF
- employs a complex generation pipeline composed of multiple distinct models (text-to-image, image-to-raw 3D, 3D object captioning and attribute prediction, 3D geometry refinement, PBR material generation and refinement, etc.)
- take about 1 minute to generate a 3D object though its pipeline
Despite these extensive resources and refinement steps, Rodin (Gen-1 RLHF V0.9) still:
- struggles to generate intricate and precise structures such as leaves and fur
- often fails to faithfully adhere to the provided image and text conditions
Rodin Stage-1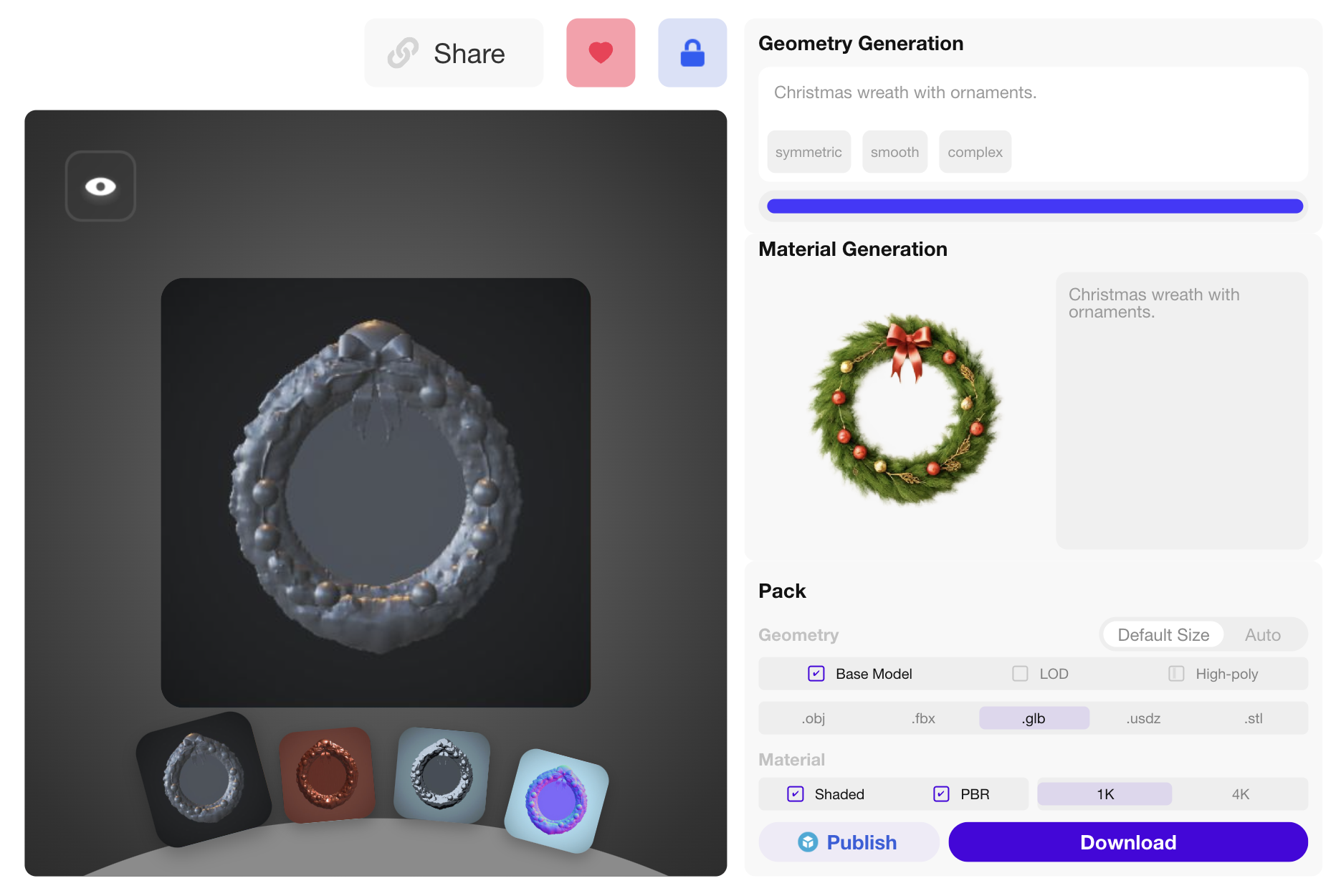
|
Rodin Final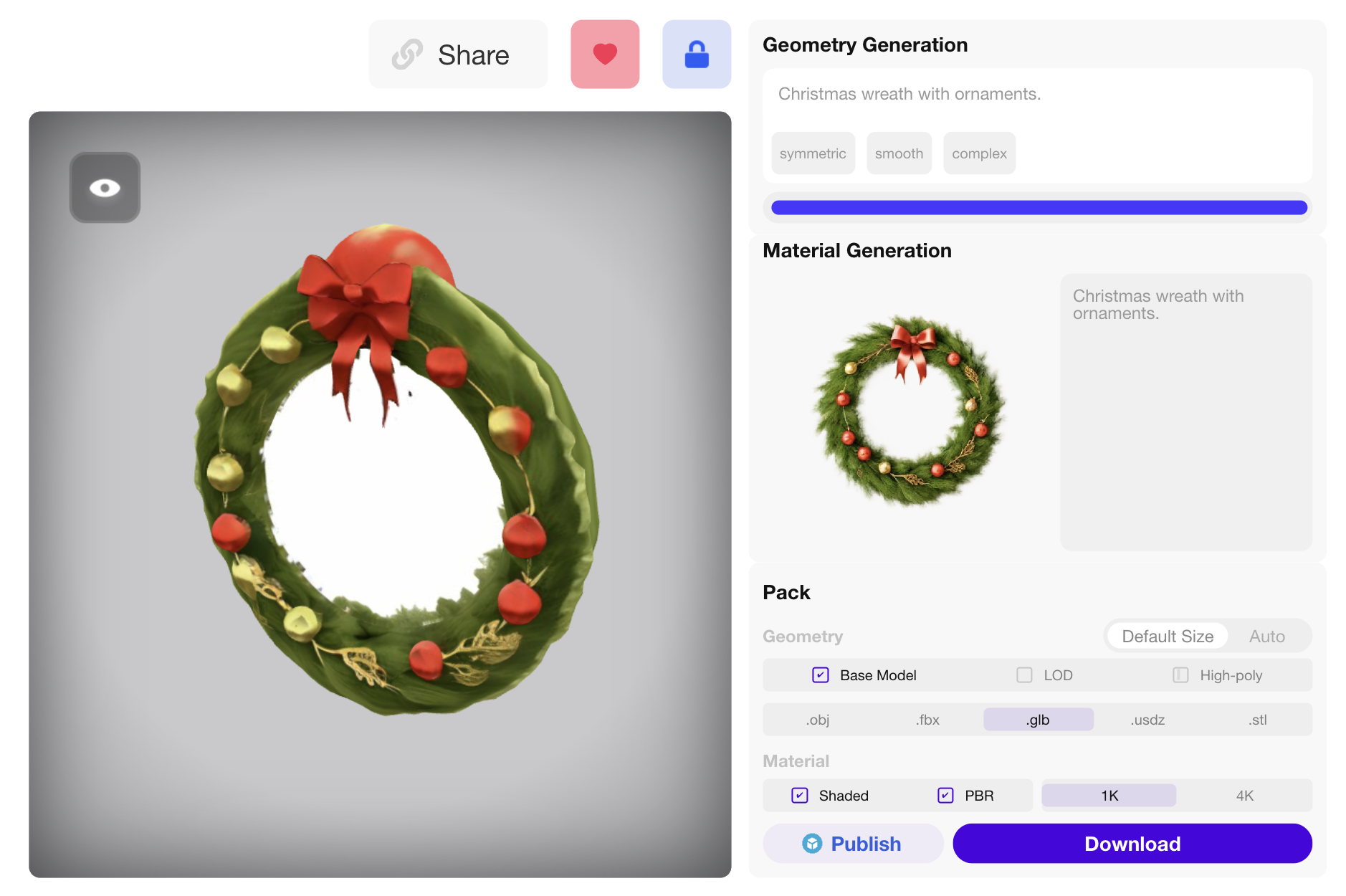
|
Ours (1~2s) |
| Prompt: "A fragrant pine Christmas wreath" | ||
Rodin Stage-1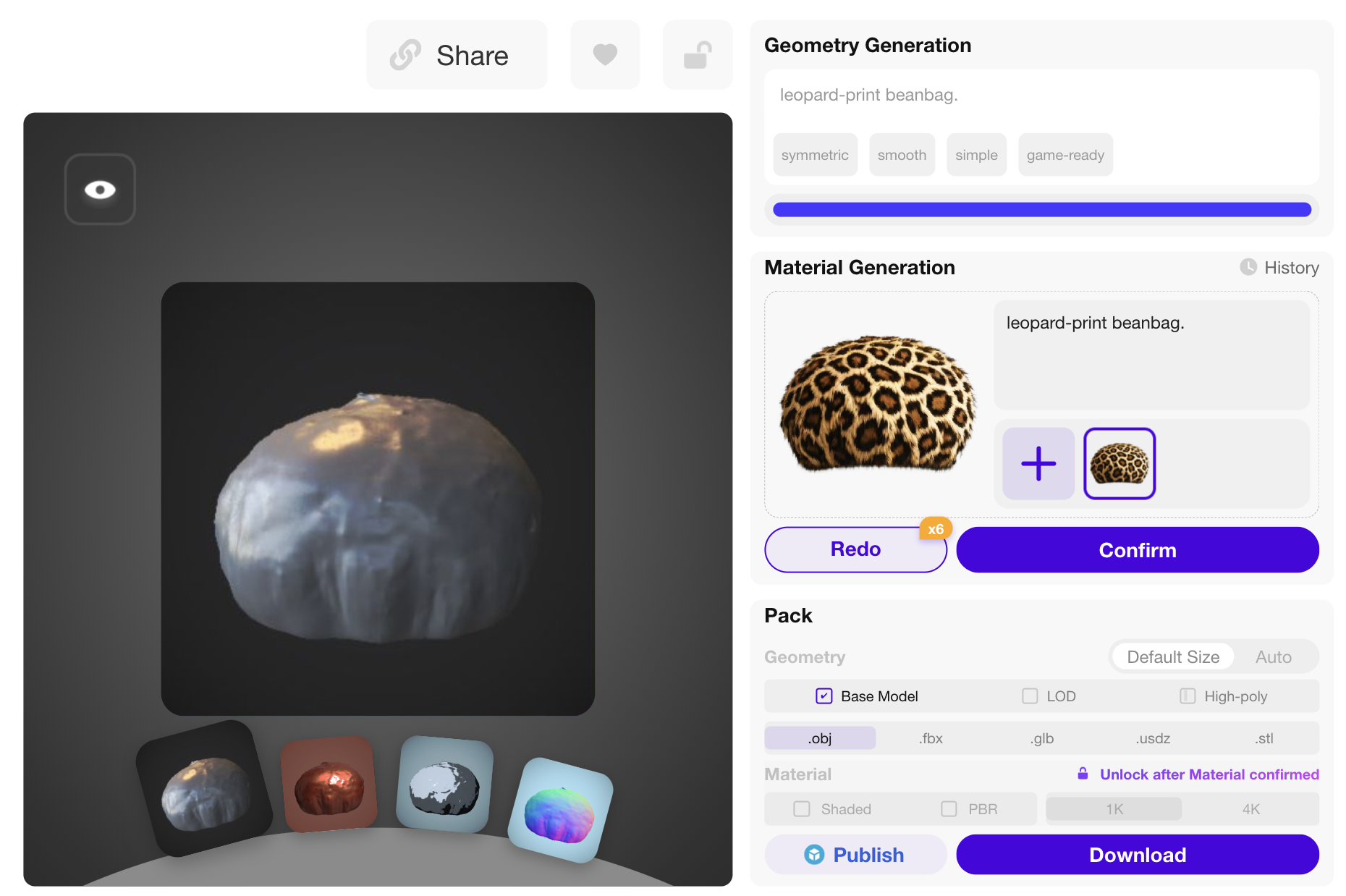
|
Rodin Final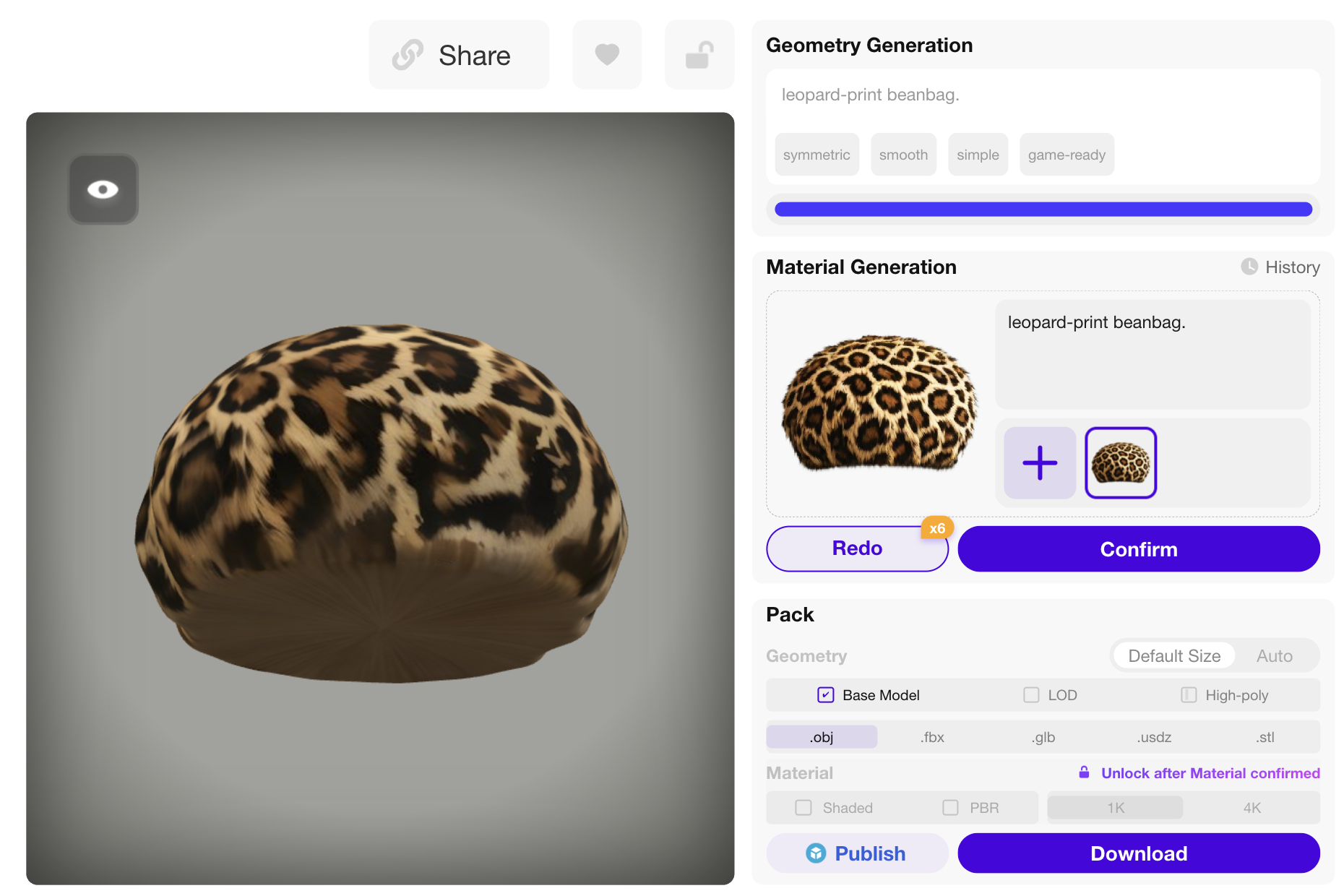
|
Ours (1~2s) |
| Prompt: "A faux-fur leopard print hat" | ||
Rodin Stage-1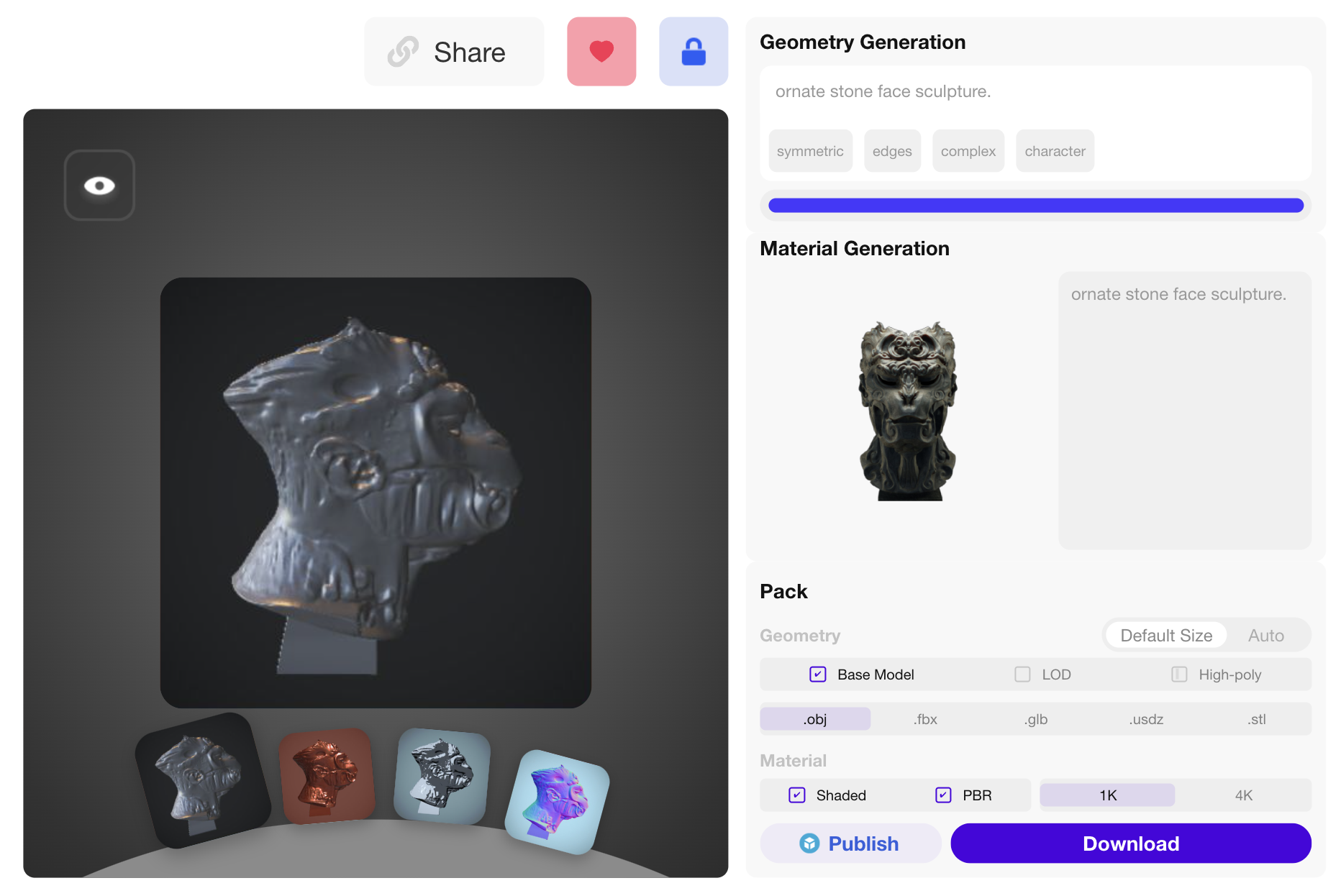
|
Rodin Final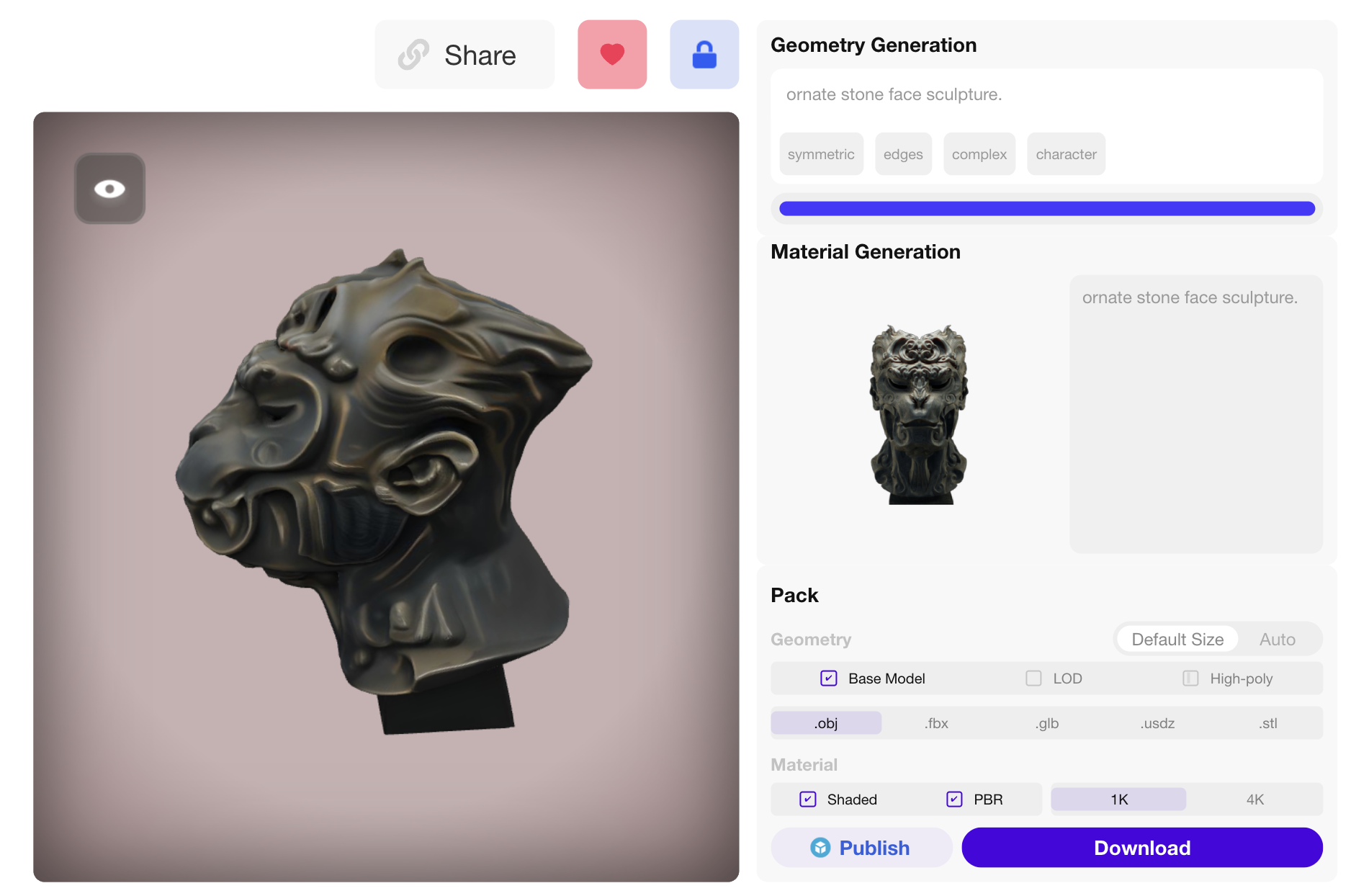
|
Ours (1~2s) |
| Input Image + Prompt: "A sculpture" | ||
Rodin Stage-1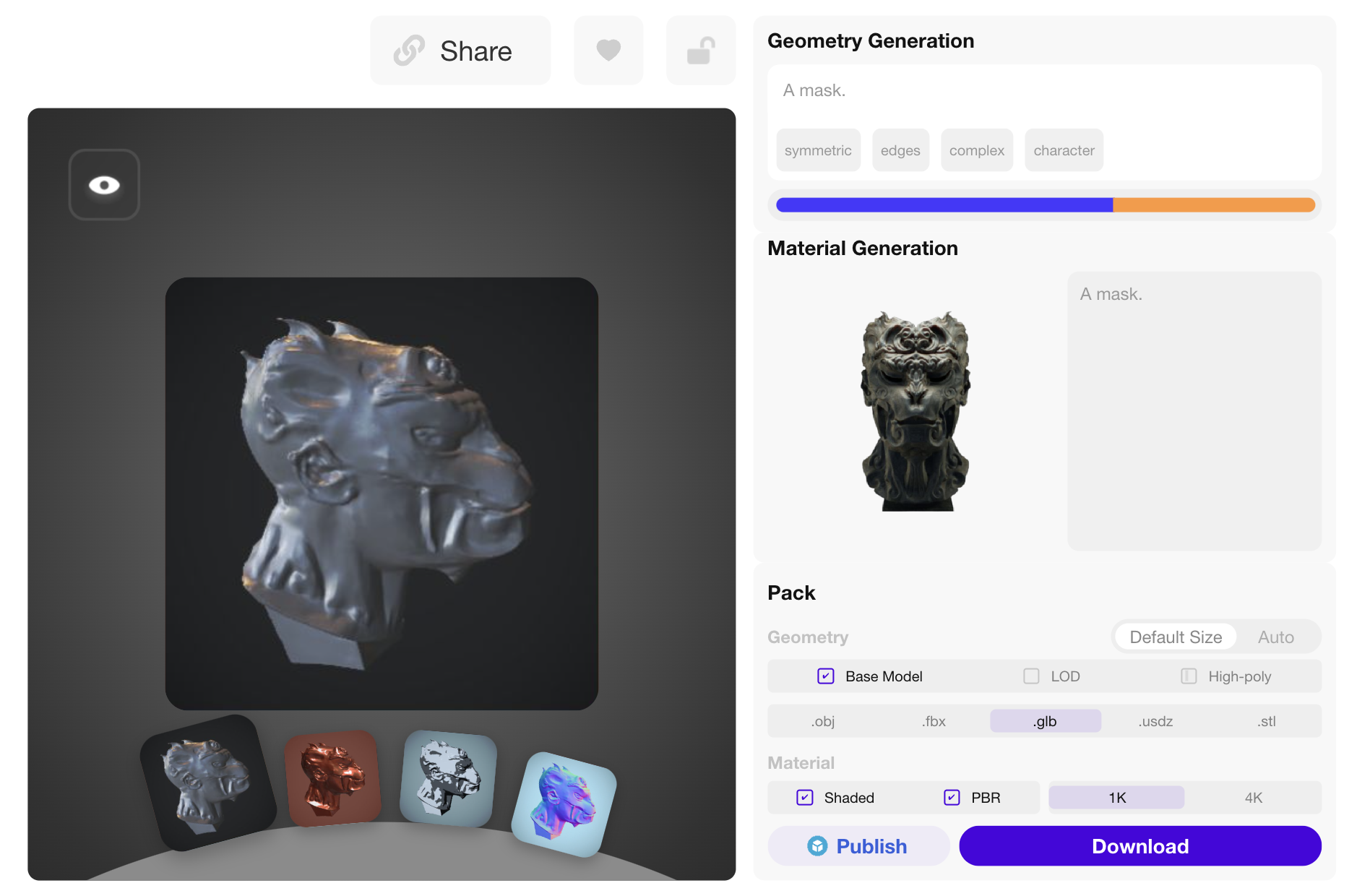
|
Rodin Final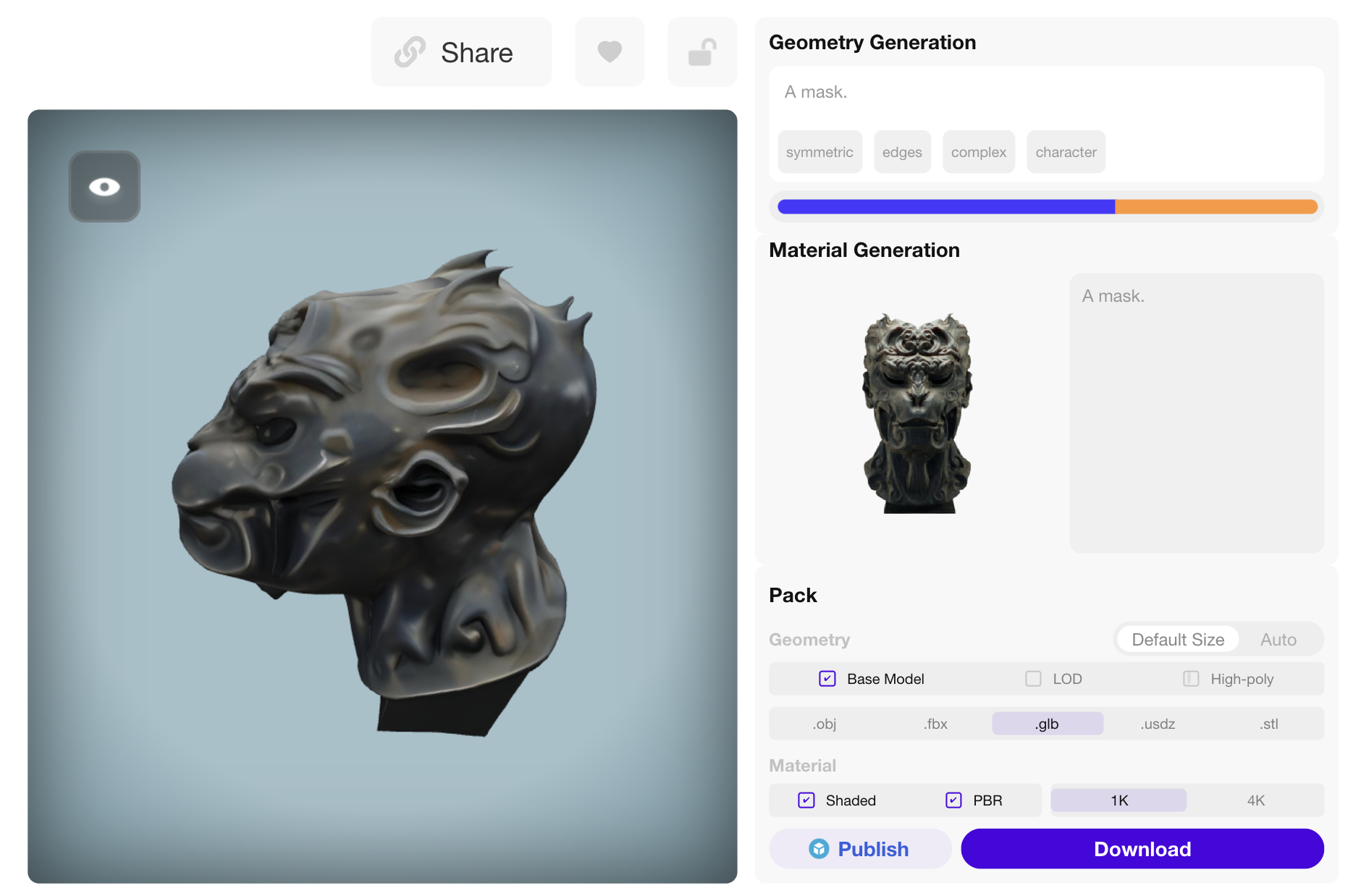
|
Ours (1~2s) |
| Input Image + Prompt: "A mask" | ||